
Matter is an open-source connectivity standard for smart homeand IoT (Internet of Things) devices. It aims to improve interoperability and compatibility between different manufacturer and security, and always allowing local control as an option.
do loop
do while loop
In many computer programming languages, a do while loop is a control flow statement that executes a block of code and then either repeats the block or exits the loop depending on a given booleancondition.
The do while construct consists of a process symbol and a condition. First the code within the block is executed. Then the condition is evaluated. If the condition is true the code within the block is executed again. This repeats until the condition becomes false.

Do while loops check the condition after the block of code is executed. This control structure can be known as a post-test loop. This means the do-while loop is an exit-condition loop. However a while loop will test the condition before the code within the block is executed.
This means that the code is always executed first and then the expression or test condition is evaluated. This process is repeated as long as the expression evaluates to true. If the expression is false the loop terminates. A while loop sets the truth of a statement as a necessary condition for the code's execution. A do-while loop provides for the action's ongoing execution until the condition is no longer true.
It is possible and sometimes desirable for the condition to always evaluate to be true. This creates an infinite loop. When an infinite loop is created intentionally there is usually another control structure that allows termination of the loop. For example, a break statement would allow termination of an infinite loop.
Some languages may use a different naming convention for this type of loop. For example, the Pascal and Lua languages have a "repeat until" loop, which continues to run until the control expression is true and then terminates. In contrast a "while" loop runs while the control expression is true and terminates once the expression becomes false.
With legacy Fortran 77 there is no DO-WHILE construct but the same effect can be achieved with GOTO:
INTEGER CNT,FACT
CNT=5
FACT=1
1 CONTINUE
FACT=FACT*CNT
CNT=CNT-1
IF (CNT.GT.0) GOTO 1
PRINT*,FACT
ENDFortran 90 and later does not have a do-while construct either, but it does have a while loop construct which uses the keywords "do while" and is thus actually the same as the for loop.
program FactorialProg
integer :: counter = 5
integer :: factorial = 1
factorial = factorial * counter
counter = counter - 1
do while (counter > 0) ! Truth value is tested before the loop
factorial = factorial * counter
counter = counter - 1
end do
print *, factorial
end program FactorialProgregex
regular expression
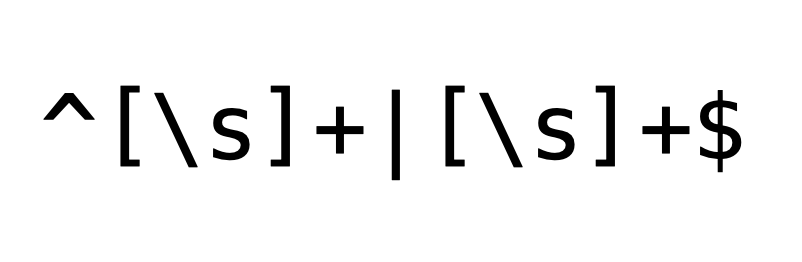
A regular expression (shortened as regex or regexp), sometimes referred to as rational expression, is a sequence of characters that specifies a match pattern in text. Usually such patterns are used by string-searching algorithms for "find" or "find and replace" operations on strings, or for input validation. Regular expression techniques are developed in theoretical computer science and formal language theory.
The concept of regular expressions began in the 1950s, when the American mathematician Stephen Cole Kleene formalized the concept of a regular language. They came into common use with Unix text-processing utilities. Different syntaxes for writing regular expressions have existed since the 1980s, one being the POSIX standard and another, widely used, being the Perl syntax.
Regular expressions are used in search engines, in search and replace dialogs of word processors and text editors, in text processing utilities such as sed and AWK, and in lexical analysis. Regular expressions are supported in many programming languages. Library implementations are often called an "engine", and many of these are available for reuse.
For Shortcuts, a good resource here and here.
Regular Expression (Regex) Syntax
A Regular Expression (or Regex) is a pattern (or filter) that describes a set of strings that matches the pattern. In other words, a regex accepts a certain set of strings and rejects the rest.
A regex consists of a sequence of characters, metacharacters (such as ., \d, \D, \s, \S, \w, \W) and operators (such as +, *, ?, |, ^). They are constructed by combining many smaller sub-expressions.
Matching a Single Character
The fundamental building blocks of a regex are patterns that match a single character. Most characters, including all letters (a-z and A-Z) and digits (0-9), match itself. For example, the regex x matches substring "x"; z matches "z"; and 9 matches "9".
Non-alphanumeric characters without special meaning in regex also matches itself. For example, = matches "="; @ matches "@".
Metacharacters ., \w, \W, \d, \D, \s, \S
A metacharacter is a symbol with a special meaning inside a regex.
The metacharacter dot (
.) matches any single character except newline\n(same as[^\n]). For example,...matches any 3 characters (including alphabets, numbers, whitespaces, but except newline);the..matches "there", "these", "the", and so on.\w(word character) matches any single letter, number or underscore (same as[a-zA-Z0-9_]). The uppercase counterpart\W(non-word-character) matches any single character that doesn't match by\w(same as[^a-zA-Z0-9_]).In regex, the uppercase metacharacter is always the inverse of the lowercase counterpart.
\d(digit) matches any single digit (same as[0-9]). The uppercase counterpart\D(non-digit) matches any single character that is not a digit (same as[^0-9]).\s(space) matches any single whitespace (same as[ \t\n\r\f], blank, tab, newline, carriage-return and form-feed). The uppercase counterpart\S(non-space) matches any single character that doesn't match by\s(same as[^ \t\n\r\f]).
Regex's Special Characters
These characters have special meaning in regex (I will discuss in detail in the later sections):
metacharacter: dot (
.)bracket list:
[ ]position anchors:
^,$occurrence indicators:
+,*,?,{ }parentheses:
( )or:
|escape and metacharacter: backslash (
\)
Escape Sequences
The characters listed above have special meanings in regex. To match these characters, we need to prepend it with a backslash (\), known as escape sequence. For examples, \+ matches "+"; \[ matches "["; and \. matches ".".
Regex also recognizes common escape sequences such as \n for newline, \t for tab, \r for carriage-return, \nnn for a up to 3-digit octal number, \xhh for a two-digit hex code, \uhhhh for a 4-digit Unicode, \uhhhhhhhh for a 8-digit Unicode.
FPE
File Provider Extension
An extension other apps use to access files and folders managed by your app and synced with a remote storage.

The framework has two different starting points for building your File Provider extension.
NSFileProviderReplicatedExtension
The system manages the content accessed through the File Provider extension. Available in macOS 11+ and iOS 16+.
The extension hosts and manages the files accessed through the File Provider extension. Available in iOS 11+.
The replicated extension takes responsibility for monitoring and managing the local copies of your documents. The file provider focuses on syncing data between the local copy and the remote storage—uploading any local changes and downloading any remote changes. For more information, see Replicated File Provider extension.
The nonreplicated extension manages a local copy of the extension’s content, including creating and managing placeholders for remote files. It also syncs the content with your remote storage. For more information, see Nonreplicated File Provider extension.

FUSE

Filesystem in Userspace (FUSE) is a software interface for Unixand Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a bridge to the actual kernel interfaces.
FUSE is available for Linux, FreeBSD, OpenBSD, NetBSD (as puffs), OpenSolaris, Minix 3, macOS, and Windows.
BTO
built to order



